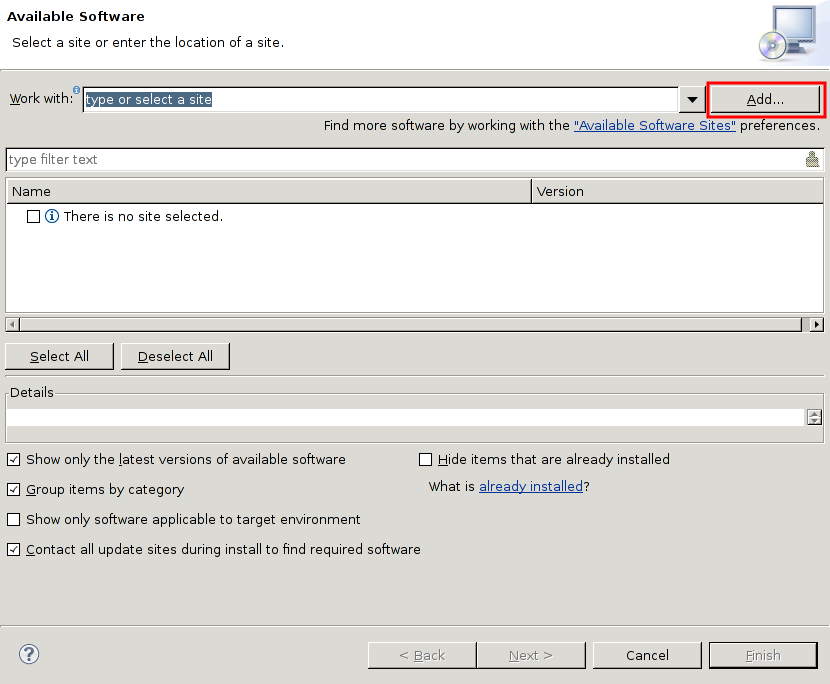
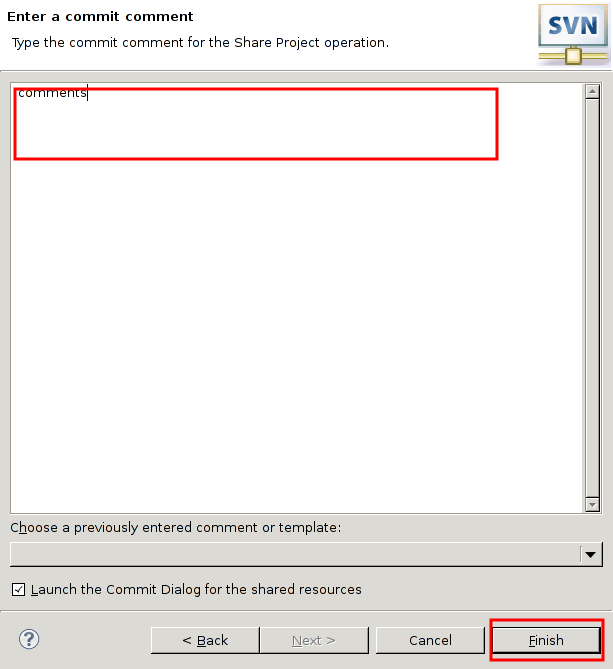
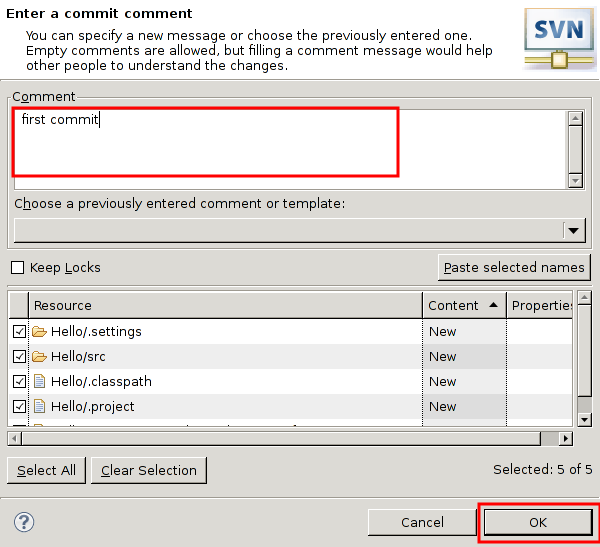
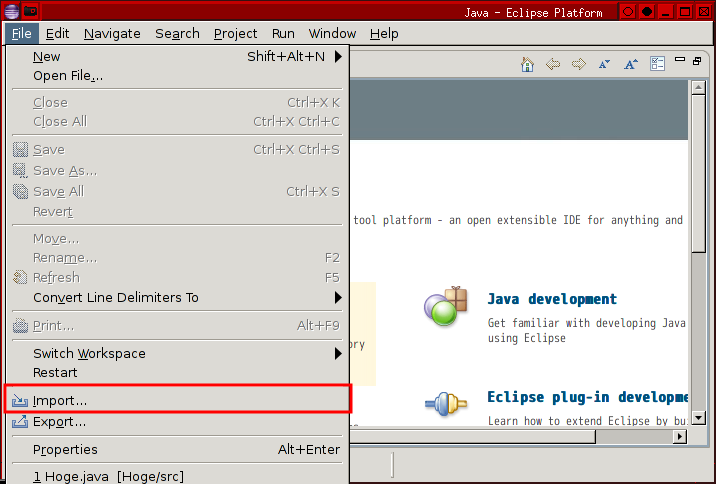
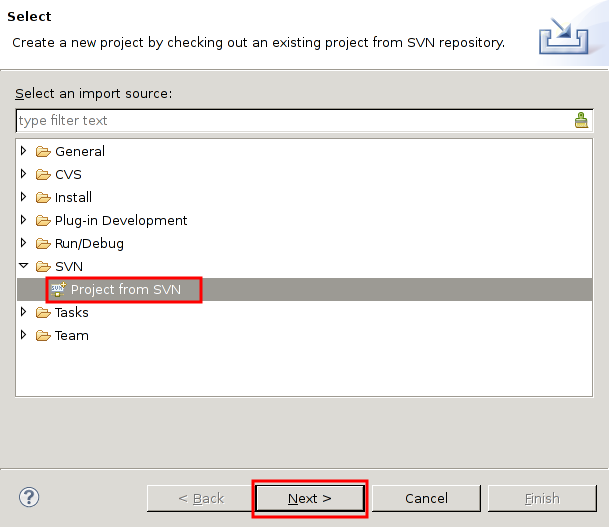
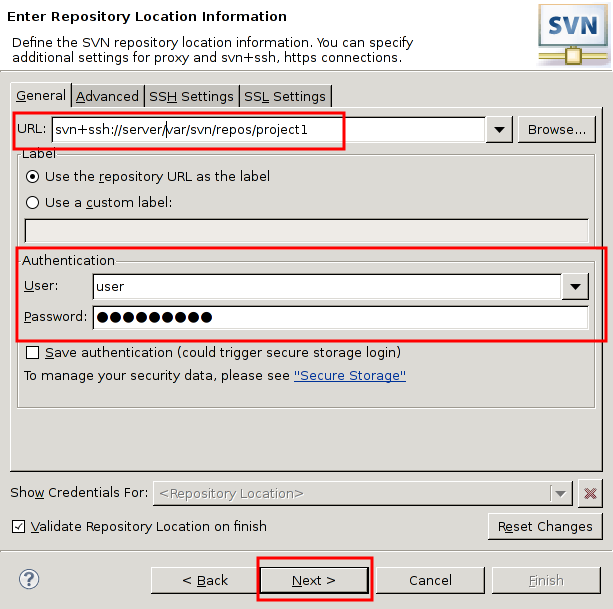
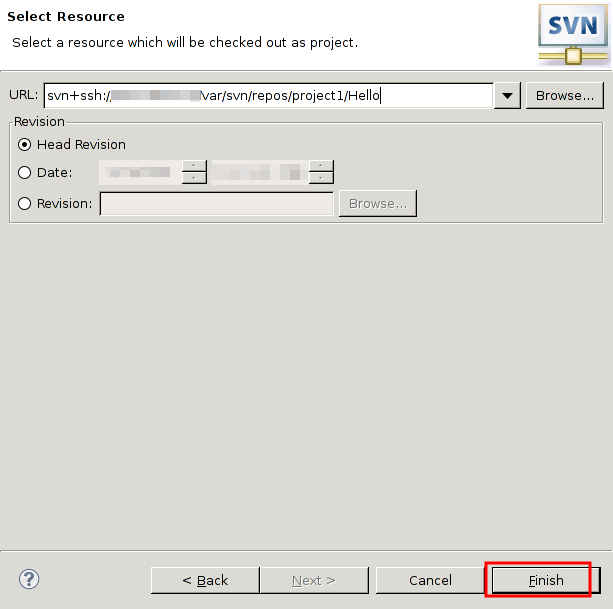
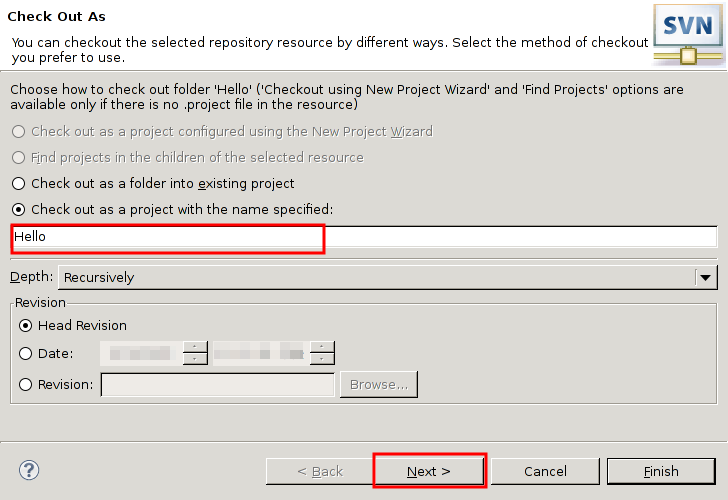
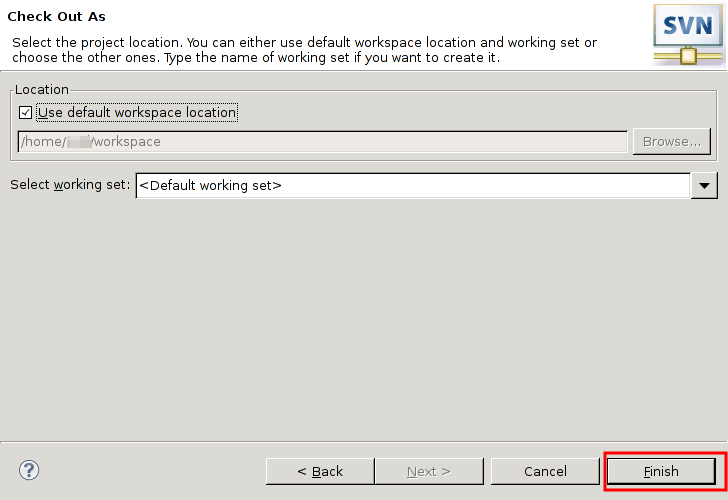
本稿は私のPython学習のメモやまとめ、特にPythonの基本をまとめたものである。学習には主に次の2つの情報源を使用した。
単純文とは、単一の論理行内に収められる文のことである。
いくつかの言語では、代入や複合代入は演算の1つであり、式文として記述される。しかしPythonでは、それらは文として独立している。とはいえ、以下のような単純な代入ではその違いは感じないだろう。
v = 5
しかし、代入演算のように代入の演算結果を利用しようとすれば、エラーとなる。
v = (w = 5)
とはいえ次のように代入した変数の値を別の変数に代入するのは、当然可能である。
v = w = 5
また、Pythonでは次のようにカンマで区切って複数の変数を1文で代入することが可能である。
v, w = 5, 10
この文では、vに5を、wに10を代入している。
代入文は項数に限らず、まず右辺の式のリストを評価し、その後ターゲットのリストの左から右へ順番に代入していく。すなわち次の式はvにwの値を、wに元のvの値を代入する。
v, w = w, v
代入とは名前(識別子)をオブジェクトに束縛、または再束縛することである。代入文では既にその名前が束縛されている場合、オブジェクトの参照カウントを1つ減らす。もしオブジェクトの参照カウントが0になった場合、オブジェクトは解放され、そのデストラクタが呼び出される。
>>> class Hoge:
... def __del__(self): # デストラクタ
... print("release")
...
>>> v = Hoge()
>>> v = 0
release
>>> x = y = Hoge()
>>> x = 1
>>> y = 2
release
del文は指定した名前の束縛を解除し、オブジェクトの参照カウントを1つ減らす。もしオブジェクトの参照カウントが0になった場合、オブジェクトは解放され、そのデストラクタが呼び出される。
del x
もし名前が未束縛ならば、NameError例外が送出される。
また、del文はカンマで区切って複数の名前を指定できる。その際、ターゲットは左から右に順に再帰的に削除される。
式文とは演算を行う文のことである。Pythonの演算子の種類と計算順序は以下を参照されたし。
演算子の優先順位は表の上に行くほど高く、下に行くほど低い。同じ優先順位を持つ場合、結合/連鎖に従って評価順が決まる。
| 演算子 | 機能 | 結合/連鎖 |
|---|
- (expressions...)
- [expressions...]
- {key:value...}
- {expressions...}
| | |
- x[y]
- x[y:z]
- x.y
- func([arg ...])
| | →結合 |
| べき数 | ←結合 |
| 単項演算子 |
|
/は除算演算で、//は切り捨て除算演算である。除算演算は小数まで計算する。モジュロ演算の結果は、0か符号が常に除数(この場合y)と同じになる。モジュロ演算の結果の絶対値は、常に除数以下になる。また、Pythonでは、切り捨て除算演算結果と除数の積に剰余を加えた値は、元の値と常に等しい。
| →結合 |
|
| 算術シフト演算 |
| ビット単位AND |
| ビット単位XOR |
| ビット単位OR |
- x in S
- x not in S
- x is y
- x is not y
- x < y
- x <= y
- x == y
- x != y
- x >= y
- >
|
比較演算。"is"や"is not"は同一性の比較で、"in"や"not in"はデータ構造の帰属のチェックの演算である。また、比較演算はオーバーロードされている。以下にいくつかの型の場合を紹介する。
| 型 | 機能 |
|---|
| 数値 | 数学的に大小を比較。 |
| bytes | 辞書順に大小を比較。 |
| 文字列 | 各文字の文字コードの大小を順に比較。 |
| リスト | 各要素を順に比較し要素の大小を比較。 |
| set | スーパセットやサブセットの判断。 |
| →連鎖 |
| 論理否定 | |
| 論理積 | →連鎖 |
| 論理和 |
| 条件演算(3項演算) | |
| lambda [x, ...] : expression
| ラムダ式。
v = lambda x, y : x + y
v(1, 2)
| |
break文はwhile文やfor文などのループを終了させる。もしelse節があってもそれは無視される。
continue文はwhile文やfor文などのループの次の周期の処理へ移動させる。
return文は関数定義内で現れ、制御を関数呼び出し側に戻して指定した値を、式を指定した場合はその評価結果の値を返す。
def func():
return 5
返り値は省略可能で省略した場合はNoneが返される。また、return文がなく関数の最後まで行った場合も同様である。return文はジェネレータ関数の中では記述できない。
ジェネレータ関数では、return文の代わりにyield文を使用する。というよりもyield文を使用した関数定義はジェネレータ関数となる。ジェネレータ関数でreturn文を使用するとエラーとなる。ジェネレータ関数はジェネレータオブジェクトを生成する。例えばこのようなジェネレータ関数を定義したとする。
def myGenerator():
i = 0
while i < 5:
yield i
i += 1
このコードはジェネレータオブジェクトの__next__関数で呼び出され、yield文までが処理される。そして次に__next__関数が呼び出されると、yield文の次の文から処理され、関数定義の末尾か次のyield文まで実行される。
>>> for x in myGenerator():
... print(x)
...
0
1
2
3
4
ジェネレータ関数の詳細は
「ジェネレータ関数」で述べる。
global文は指定した名前(識別子)をグローバル変数として解釈するようにする文である。global文にはカンマで区切って複数指定できる。
関数内の名前(識別子)のスコープのことをローカルスコープという。Pythonでは、関数内で別の関数を定義できるため、内側と外側の関数で名前の競合が発生する。nonlocal文は指定した名前(識別子)が最も近傍のローカルスコープで以前に束縛された変数を参照するようにする。
指定した例外を送出する。
def div(x, y):
if y==0:
raise ZeroDivisionError
return x // y
何も指定しなかった場合、現在のスコープで最終的に有効になっている例外を再送出する。もしもそのような例外がない場合TypeError例外が送出される。
例外はtry文で受け取り処理を行うことができる。例外については「try文」で詳述する。
条件が偽だった場合にAssertionErrorを送出する文である。
例えばこのような関数を定義したとする。
def test(left, right):
assert left < right
条件が真の場合と偽の場合の結果は以下のようになる。
>>> test(1, 3)
>>> test(3, 1)
Traceback (most recent call last):
File "", line 1, in
File "", line 2, in test
AssertionError
pass文は意味のない文であり、構文上何か必要な場合に記述する。例えば、関数定義で処理内容を記述しない場合はこのように書く。
def func(): pass
import文はモジュールのロードに使用する文である。モジュールの読み込み先ディレクトリは、sysモジュールのpathで定義されている。
import文には、asやfromキーワードの組合せでいくつかのパターンがある。以下にいくつか例を示す。
*を指定した場合、_を接頭辞とする名前を除く全てのメンバをロードする。ただし、モジュールに__all__という名前のメンバがあれば、__all__に含まれる名前のメンバのみがロードされる。
import文では、ロードするモジュールは、カンマで区切って複数記述できる。また、指定したモジュールがなかった場合、ImportError例外が送出される。
Pythonスクリプトを記述し、ライブラリとして利用できるようにしたファイルをモジュールという。モジュールとモジュールを利用したコードのサンプルを以下に示す。
なおhoge.pyで記述したドキュメントを記述した文字列については、「ドキュメンテーション文字列」で後述する。
- hoge.py
#!/usr/bin/python3
# -*- coding: utf-8 -*-
"サンプルモジュールを定義"
class Hoge:
"サンプルモジュールのクラス"
def add(self, addee:"被加数", adder:"加数") -> "和":
"サンプルモジュールのメンバ関数"
return addee + adder
- fuga.py
#!/usr/bin/python3
# -*- coding: utf-8 -*-
import hoge
h = Hoge()
print(h.add(1, 2))
全ての機能を1つのモジュールに集約するのではなく、複数のモジュールを記述し、それを一括にロードする方法がある。それがパッケージである。パッケージはモジュールと同様にimport文でロードできる。パッケージとは普通のディレクトリであり、必ず__init__.pyというファイルが格納されている。__init__.pyは存在していれば中身が空でも構わない。パッケージの内容は__init__.pyの中身となる。すなわち、"hoge/"というディレクトリのパッケージがあるとする。この時、"import hoge"と行うとロード対象は"hoge/__init__.py"の中身となる。
複合文とは、2行以上の複数の論理行に収められる文のことである。
if文は分岐文である。if文には次の3つのキーワードがある。
Cではifとelseしかなく、複数の条件を書く場合はelseの中にifを書いていたが、Pythonではelif節というものが存在する。if文は1個のif節と、1個か0個のelse節、0個以上のelif節からなる。文法的に、はじめにif節、次にelif節、最後にelse節を書く。
elifはifが偽の時に処理され、複数のelifがある場合は上の方が先に評価される。
def func(i):
if i < 10:
print("10未満である")
else:
print("10以上である")
while文は繰り返し文の1つである。
while 条件式:
処理1
[else:
処理2]
はじめに条件式が評価され、その結果が真であれば、処理を実行する。その後、処理が終了する度に条件式が評価され、偽になるまで処理を続ける。
また、Pythonのwhile文にはelse節がある。
for x in 1, 2, 3, 4:
print(x)
else:
print("loop end")
もしループの条件式の評価結果が偽となった場合、ループが終了した後に実行される。ただしbreak文で終了した場合、else節はスキップされる。
for文は繰り返し文の1つである。Pythonでは、イテレータを使用し各要素に何らかの処理を行うような場合にfor文を使用する。
for ターゲットリスト in 式リスト :
処理1
[else:
処理2]
ターゲットリストや式リストは次のように記述する。
>>> for x in 0,1,2,3:
print(x)
また、以下のようにターゲットリストには複数の変数を指定できる。
>>> for x, y in [0,10], [5,20], [10,30]:
... print(str(x) + "," + str(y))
...
0,10
5,20
10,30
各式は最初に1度だけ評価され、イテレータが生成される。例えば式リストに組み込み関数rangeを使用し、"range(1, 5)"と記述した場合、"[1, 2, 3, 4]"となり、各要素が順に代入される。
>>> def func():
... print("hoge")
... return 1
...
>>> for x in func(), func():
... print("fuga")
...
hoge
hoge
fuga
fuga
Pythonのfor文にはelse節がある。もしループの条件式の評価結果が偽となった場合、ループが終了した後に実行される。break文で終了した場合、else節はスキップされる。
with文を使用すると、開始処理と終了処理があるような場合に、それを明示的に表現した簡潔なコードを記述できる。
with open("./write.txt", "w") as f:
f.write("Hello\n")
f.write("ハロー\n")
f.write("はろー\n")
with文では、処理の最初に__enter__関数が、最後に__exit__関数が呼び出される。with文で__enter__関数の処理が正常に実行されたならば、__exit__関数が呼び出されることが保証される。
もしwithのスイート内で例外が送出したら、型と値、トレースバックが__exit__関数の引数に与えられる。それ以外の場合、各変数にはNoneが代入される。また、__exit__関数がTrueを返さなかった場合、with文は例外を送出する。__enter__関数と__exit__関数をオーバーライドする例を以下に示す。
class Cls:
def __enter__(self):
print("begin")
return self
def __exit__(self, type, value, traceback):
print("end")
return True
def func(self, str):
print(str)
実行結果は次の通りである。
>>> with Cls() as c:
... c.func()
...
begin
end
また、次のように複数の束縛を行う場合、カンマで区切って簡潔に記述できる。
with open("./write.txt", "w") as w
with open("./read.txt", "r") as r:
print(r.read(), file=w)
with open("./write.txt", "w") as w, open("./read.txt", "r") as r:
print(r.read(), file=w)
関数定義はdefキーワードを使用する。
def add(x, y):
return x + y
定義した関数は関数呼び出し演算で呼び出すことができる。
- デフォルト引数
-
関数定義では、引数を省略した際に代入されるオブジェクトを指定できる。
>>> def func(str = "default"):
... print(str)
...
>>> func("hoge")
hoge
>>> func()
default
- 可変引数
-
Pythonでは、引数の数が任意個数の関数を定義できる。
- *arg
-
タプル型で順に格納される。
>>> def func(arg1, *args):
... print(args)
...
>>> func(0,1,2,3,4,5)
(1, 2, 3, 4, 5)
- **arg
-
辞書型で格納される。
>>> def func(arg1, **args):
... print(args)
...
>>> func(0)
{}
>>> func(0, v=1, w=2)
{'w': 2, 'v': 1}
- 引数名指定
-
関数呼び出しで引数を渡す際、引数の名前を指定して渡すことができる。
>>> def add(addee, adder):
... return addee + adder
...
>>> add(adder=10,addee=5)
15
関数デコレータとは、関数に機能を明示的に追加または変更するための機能である。関数定義は1つ以上の関数デコレータでラップできる。
def decorator_called(f):
def wrapper():
print("called ", f.__name__)
return f()
return wrapper
@decorator_called
def hello():
print("Hello, World")
hello関数を呼び出した結果を以下に示す。
called hello
Hello, World
このように関数デコレータは、関数の生成の際に関数を受け取りそれに何らかの処理を加えて関数を呼び出す。
ジェネレータ関数はイテレータの一種で、ジェネレータオブジェクトを作成する関数である。Pythonでは、関数定義でreturn文の代わりにyield文を記述することでジェネレータ関数を定義できる。
def fib():
x, y = 0, 1
while True:
yield x
x, y = y, x + y
ジェネレータのコードは、はじめに関数のコードの頭からyield文まで処理し、次に呼び出した際はyieldの次の文からyield文まで処理する。ジェネレータのコードは、__next__関数を呼び出すことで処理される。
>>> f = fib()
>>> f.__next__()
0
>>> f.__next__()
1
>>> f.__next__()
1
>>> f.__next__()
2
>>> f.__next__()
3
>>> f.__next__()
5
このジェネレータオブジェクトをfor文で指定すると、無限に処理され続ける。これを改良したコードを以下に示す。
def fib(max):
x, y = 0, 1
while x < max:
yield x
x, y = y, x + y
これを実行すると次のようになる。
>>> f = fib(10)
>>> for x in f:
... print(x)
...
0
1
1
2
3
5
8
クラスは次のようにして定義する。
class Cls:
def __init__(self): # <コンストラクタ>
self.str = "instance" # インスタンス変数
print("called constructor")
def __del__(self): # <デストラクタ>
print("called destructor")
def func(self, arg0, arg1):
str = "local" # ローカル変数
print(self.str)
print(str)
print(arg0)
print(arg1)
コンストラクタやデストラクタ、インスタンス変数の定義もご覧の通りである。以下に実行例を示す。
>>> c = Cls()
called constructor
>>> c.func(0, 1)
instance
local
0
1
>>> del c
called destructor
また、Pythonにはコンストラクタ(__init__)とは別にインスタンスアロケータ(__new__)というものがある。
__new__は静的メソッドで、新しいインスタンスを生成する際に自動的に呼び出される。__init__の第1引数がインスタンスであるのに対し、__new__にはクラスが与えられる。__new__()がclsのインスタンスを返さない限り、インスタンスの__init__は呼び出されない。なお__init__と__new__の第2引数以降は同じものが与えられる。
class Hoge:
def __new__(cls):
print("new Parent")
return super().__new__(cls)
def __init__(self):
print("init Parent")
このクラスを利用した例は次の通りとなる。
>>> h = Hoge()
new Parent
init Parent
__new__は変更不能な型 (int, str, tuple など) のサブクラスでインスタンス生成をカスタマイズするために使用される。それゆえ、基本的に__new__をオーバーライドする必要はない。
- 継承
-
継承は次のように記述する。
class Sub(Parent):
pass
また、Pythonは多重継承をサポートする。多重継承では、基底クラスをカンマで区切って記述する。
class Sub(Parent1, Parent2):
pass
オブジェクトの型を取得する場合はtype関数を使用する。また、オブジェクトの型が指定したクラスか、そのサブクラスであるかを調べたい場合は、isinstanceを使用する。
>>> class Parent: pass
...
>>> class Child(Parent): pass
...
>>> p, c = Parent(), Child()
>>> isinstance(p, Parent)
True
>>> isinstance(c, Parent)
True
- カプセル化
-
Pythonでは、メンバへのアクセス制御の種類はあまり多くない。
- 非公開(private)な名前を設定する場合、名前の接頭辞に__を付ける。
- 前述以外の名前は全て公開(public)な名前となる。
なおPythonでは、非公開な名前はPythonによって名前を変更されるだけで、アクセスは可能である。
- ポリモフィズム(多態化)
-
Pythonでは、メンバ関数は標準でオーバーライド可能である。
- 演算子の多重定義
-
Pythonでは、いくつかの特殊関数をオーバーロードすることで演算子の多重定義を実装できる。以下に例をいくつか紹介する。
| 関数名 | 演算子 | サンプル |
|---|
| __add__(self, other) |
+ |
| __sub__(self, other) |
- |
| __mul__(self, other) |
* |
| __truediv__(self, other) |
/ |
| __floordiv__(self, other) |
// |
| __mod__(self, other) |
% |
| __pow__(self, other) |
** |
| __lshift__(self, other) |
<< |
| __rshift__(self, other) |
>> |
| __or__(self, other) |
| |
| __and__(self, other) |
& |
| __xor__(self, other) |
^ |
| __lt__(self, other) |
< |
| __le__(self, other) |
<= |
| __eq__(self, other) |
== |
| __ne__(self, other) |
!= |
| __gt__(self, other) |
> |
| __ge__(self, other) |
>= |
| __neg__(self) |
- |
| __pos__(self) |
+ |
| __call__(self, [args]) |
() |
この他にも累積代入文や型チェックなどをオーバーライドするために、さまざまな特殊関数が用意されている。
- クラス関数
- クラス変数
-
クラス関数やクラス変数は次のように関数デコレータで定義できる。
class Cls:
@classmethod
def set(cls, v):
cls.v = v
@classmethod
def p(cls):
print(cls.v)
以下に実行例を示す。
>>> o1, o2 = Cls(), Cls()
>>> o1.set("hoge")
>>> o2.p()
hoge
クラスデコレータとは、クラス定義に処理を加える機能のことである。
import sys
def py_major_version(major):
def wrap(cls):
if sys.version_info[0] < major:
raise RuntimeError("version error")
return cls
return wrap
@py_major_version(3)
class Hoge:
pass
このコードは、Pythonのメジャーバージョンが2以下の場合に例外を発生させる。
メタクラスは、クラスを生成するためのクラスである。
def ham(self, arg):
print(arg)
class MetaSpam(type): #組込み型typeを基に
@classmethod
def __prepare__(metacls, name, bases):
print(name)
print(bases)
return {'ham':ham}
class Hoge(metaclass=MetaSpam):
pass
メタクラスは次のように指定する。
- class クラス名(metaclass=メタクラス)
- class クラス名(親クラス, metaclass=メタクラス)
- class クラス名(metaclass=メタクラス, 引数名=引数)
try文は例外処理やクリーンアップ処理を行う文である。いくつかの言語では、エラー発生を通知するための手段として例外処理機構を持つ。例外処理機構は、呼び出し側へのエラー通知機能や、エラー処理とエラー通知の分離などさまざまな特徴を持つが、本稿ではそれらの詳細については言及しない。
try文は、以下のように例外が送出し得る文をtry節に記述し、送出するとexcept節で受け取ることができる。else節を記述した場合、制御がtry節の末尾までいった場合に実行される。これに対し、finally節を記述した場合、どの節を処理したかに関わらず必ず最後に呼び出される。
def div(x, y):
try:
result = x // y
except ZeroDivisionError:
result = "Error"
finally:
print(result)
except節とelse節、finally節は省略可能であり、except節は複数記述でいる。ただし、except節とfinally節の両方を省略することはできない。
また、except節は送出された例外オブジェクトをasで指定した名前に束縛することができる。
class myError(Exception):
msg = ""
class Cls:
def func(self):
e = myError()
e.msg = "error"
raise e
c = Cls()
try:
c.func()
except myError as my:
print(my.msg) # 画面に"error"を出力
例外に使用するクラスは、BaseExceptionを例外していなければならない。しかし通常独自の例外を定義する場合、ExceptionというBaseExceptionのサブクラスを継承する。
Pythonには、コメントは#から行末までの1つしかない。
func() # 関数funcを呼び出す。
Pythonでは、コメントとは別にドキュメントを読み書きする仕組みがある。関数のドキュメントはhelp関数で閲覧できる。
- 関数アノテーション
-
関数の引数と返り値を説明するドキュメント(関数アノテーション)は次のように記述できる。
def sum(addee:"被加数", adder:"加数") -> "和":
return addee + adder
- ドックストリング
-
関数やクラス、モジュールの説明(ドックストリング)は、スイート内の(Pythonの)文が始まる前に文字列リテラルを置くことで記述できる。
def sum(addee:"被加数", adder:"加数") -> "和":
"""
2つの値を受け取ってその加算結果を返す
"""
return addee + adder
Pythonには、組み込みの型がいくつかある。以下にいくつか紹介する。
- 論理型(bool)
-
論理型はTrueかFalseの2つのいずれかの値を持つ。リテラルの書き方もまたTrueかFalseである。
- 数値型
-
数値型には次のようなものがある。
| 型 | 説明 | リテラルの例 |
|---|
| 整数型(int) | メモリサイズの制限があるだけで無限の定義域を持つ。負の数は2の補数で表しており符号ビットが左に無限に続くような値となる。 | 10, 0x1a, 017, 0b1011 |
| 浮動小数点型(float) |
他の言語同様2進数で保持されるため、10進数との誤差が生じる。例えば"0.1+0.1+0.1"は"0.30000000000000004"となるため、"0.1+0.1+0.1==0.3"は偽となる。
| 3.14, 1e3 |
| 複素数型(complex) | | 3j |
数値型のための関数には、絶対値を求める関数absやべき数を求める関数pow、文字列の文字コードを取得する関数ordなどがある。
- NotImplemented
- Ellipsis
-
Python独特の型で、それぞれ未実装と省略を表す型。値はそれぞれ1種類しかなく、それぞれ型と同じ名前のリテラルである。評価結果は必ず真となる。
- None
-
Cのvoidに該当する型として、Pythonには値が存在しないことを表すNone型がある。Cのvoid型がオブジェクトも値も持っていないのに対し、None型のオブジェクトは1つだけあり、値も1つだけある。NoneはCのnilにも該当し、Noneの評価結果は常に偽となる。また、Pythonでは関数の返り値を省略した場合はこのリテラルが返される。
Pythonのデータ構造には次の3種類がある。
- シーケンス型
-
シーケンス型はシーケンシャルに処理するためのデータ構造である。シーケンス型には以下のようなものがある。
| 型 | 説明 | リテラル例 |
|---|
| tuple | イミュレータブルな配列 | (0, 1, 2) |
| list | ミュータブルな配列 | [0, 1, 2] |
| string | 文字列 | "aiueo" |
シーケンス型の詳細は「シーケンス型」で説明する。
- 集合型
-
集合型は非シーケンスなデータ構造である。
| 型 | 説明 | リテラル例 |
|---|
| set | 格納順が不定なデータ構造 | {1, 2, 3} |
- 辞書型
-
辞書型はキーでデータにアクセスするデータ構造である。
| 型 | 説明 | リテラル例 |
|---|
| dict | ハッシュ | {"key1":1, "key2":"hello"} |
シーケンス型はシーケンシャルに処理するためのデータ構造である。Pythonのシーケンス型には次の3種類のものがある。
シーケンス型には次のような演算子や組み込み関数がある。
| 演算 | 説明 | 実行例 |
|---|
| x in s | 帰属であることをチェック。 |
>>> "Hello" in "Hello, World"
True
|
| x not in s | 帰属していないことをチェック。 |
>>> "Hello" not in "Hello, World"
False
|
| s1 + s2 | 2つのシーケンスを結合。 |
>>> [0,1,2,3] + [4,5,6]
[0, 1, 2, 3, 4, 5, 6]
|
| s * n | sをn個分結合。 |
>>> [1,2,3]*3
[1, 2, 3, 1, 2, 3, 1, 2, 3]
|
| n * s |
| s[i] | 指定した番号の要素にアクセス。 |
>>>"Hello"[1]
e
|
| s[i:j] | 指定した範囲を抽出したものを生成。 |
>>> (0,1,2,3,4,5,6,7,8)[1:-2]
(1, 2, 3, 4, 5, 6, 7)
|
| s[i:j:k] | 指定した範囲でk毎に取り出したシーケンスを生成。 |
>>> [0,1,2,3,4,5,6,7,8][1:-2:2]
[1, 3, 5]
|
| len(s) | 要素数を返す。 |
>>> len([0,1,2,3])
4
|
| min(s) | 要素のうち最小のものを返す。 |
>>> min([0,1,2,3])
0
|
| max(s) | 要素のうち最大のものを返す。 |
>>> max([0,1,2,3])
3
|
| s.index(x[, y[, z]]) | xと最初に一致した要素の添字番号を返す。yは検索の開始位置を、zは検索の終了位置を表す。ValueError例外を送出する。 |
>>> [4,3,2,1,0].index(3)
1
|
| s.count(x) | 指定した値がいくつあるかを返す。 |
>>> [1,2,3,1,4,1].count(1)
3
|