OS 設計・実装 -メモリ管理-
| 投稿日: | |
|---|---|
| タグ: |
OSの設計と実装に関して勉強した際のメモ。テキストにはLinuxカーネル2.6解読室を主に使用。Operating Systems Design and Implementationも時々読んだ。本稿は特にプロセスやメモリに関連するメモである。前提として,タネンバアム先生のモダンオペレーティングシステムやパタヘネ関係の知識が必要。
仮想メモリ
UNIX系OSでは,各プロセスに実際のメモリ(物理メモリ)を仮想化した仮想メモリを提供する。物理メモリがシステムで唯一の存在であるのに対し,仮想メモリはプロセス分だけ存在する。例えば伝統的な32ビットアーキテクチャ用のUNIX系OSでは,メモリアドレスが32ビット長であり,プロセスは4GBのメモリ空間(0から232-1の範囲のアドレス)を利用できる。しかし,実際にあるプロセスのアドレス0x00402310と,別のプロセスのアドレス0x00402310は,それぞれ別の物理アドレスを使用している。
仮想メモリは次のような特性や機能を持つ。
- 実際のメモリサイズよりも大きなメモリ空間
- マルチプログラミング
- 各プロセスは独立したメモリ空間を持つ。
- メモリ保護機能
- カーネルを除くプロセスは基本的に他のプロセスのメモリ空間にアクセスできない。
- セクションやセグメントなどと呼ばれるメモリ領域毎に読み書きや実行などを制限。
| 31 | 30 | 29 | 28 | 27 | 26 | 25 | 24 | 23 | 22 | 21 | 20 | 19 | 18 | 17 | 16 | 15 | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| ページ番号 | ページ内オフセット | ||||||||||||||||||||||||||||||
仮想ページ番号から物理ページ番号への変換には,ページテーブルという対応表を使用する。ページテーブルはプロセス毎に1つ存在し,プロセスがメモリにアクセスするとMMU(Memory Management Unit)というハードウェアによって自動でアドレス変換が行われる。ページテーブルはメモリ空間上に存在し,OSによって生成される。MMUはページテーブルの先頭アドレス(物理アドレス)を指すレジスタを持ち,それを利用してページテーブルにアクセスする。ページテーブルは,仮想ページ毎に次のような情報を持つ。
- 物理ページ番号
- ディスク上の位置
- 有効ビット(メモリ上にロード済かどうか)
- 読み込み可能かどうか
- 書き換え可能かどうか
- 実行可能かどうか
- ダーティビット(ページが書き換えられたかどうか)
- 参照ビット(最近参照されたかどうか。ページを追い出す基準に使われる)
| 仮想ページ番号 | 有効 | 物理ページ番号 | 読み込み可能 | 書き込み可能 | 実行可能 |
|---|---|---|---|---|---|
| 0x00000 | オン | 0xABCDE | オン | オン | オフ |
| 0x00001 | オン | 0xFF001 | オン | オフ | オフ |
| 0x00002 | オフ |
struct page_table_entry{
paddr_t phisical_page;// 物理ページ番号かディスク上のアドレス
// ここでpaddr_tは物理アドレスを表現できるサイズの符号なし整数型を表す
bool valid; // 有効ビット
bool readable; // 読み込み可能
bool writable; // 書き込み可能
bool executable; // 実行可能
bool dirty; // ダーティビット
bool refference; // 参照ビット
page_table_entry() :valid(false) {}
} page_table[1<<20]; // ページテーブル 1<<20==2**20
if (page_table[virtual_page].valid==true)
page_table[virtual_page].phisical_page
多段ページテーブル
Linuxは多段ページテーブルを使用する。多段ページでは,仮想アドレスは次のようにさらに細かいフィールドに分けられる(フィールドのサイズは不定)。
| 31 | 30 | 29 | 28 | 27 | 26 | 25 | 24 | 23 | 22 | 21 | 20 | 19 | 18 | 17 | 16 | 15 | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| ページグローバルディレクトリ | ページミドルディレクトリ | ページテーブル | ページ内オフセット | ||||||||||||||||||||||||||||
| 0x0 | 0x04 | 0x02 | 0x310 | ||||||||||||||||||||||||||||
- テーブルを指すテーブル
- ページテーブル
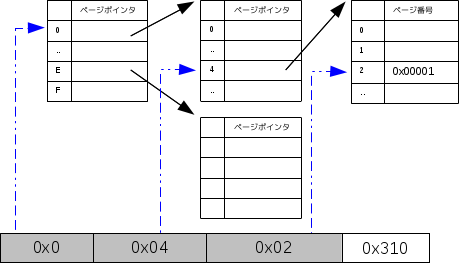
前述のようにC++で表現しようとすると次のようにな感じになる。
page_table_entry **page_table[1<<4]={NULL};
page_table[0x0] = new page_table_entry* [1<<8];
page_table[0x0][0x04] = new page_table_entry[1<<8];
page_table[0x0][0xF0] = new page_table_entry[1<<8];
- 1階層ページ
if (page_table[0x00402].valid==true) page_table[0x00402].phisical_page- 3階層ページ
if (page_table[0x0]!=NULL && page_table[0x04]!=NULL && page_table[0x02].valid==true) page_table[0x0][0x04][0x02].phisical_page
Linuxのページテーブルの実装
Linuxの多段ページテーブルは,次のようなフィールドからなる。
- バージョン2.6.12以降
ページグローバルディレクトリ ページアッパーディレクトリ ページミドルディレクトリ ページテーブル ページ内オフセット - バージョン2.6.11以前
ページグローバルディレクトリ ページミドルディレクトリ ページテーブル ページ内オフセット
- linux-2.6.12.1/mm/memory.cの782-812行目
pgd_t *pgd; // pdg_tはページグローバルディレクトリのエントリ pud_t *pud; // pdg_tはページアッパーディレクトリのエントリ pmd_t *pmd; // pdg_tはページミドルディレクトリのエントリ pte_t *ptep, pte;// pte_tはページテーブルのエントリ unsigned long pfn; struct page *page; page = follow_huge_addr(mm, address, write); if (! IS_ERR(page)) return page; pgd = pgd_offset(mm, address); // オフセット取得 if (pgd_none(*pgd) || // エントリの有無の確認 unlikely(pgd_bad(*pgd))) // エントリが不正かどうか確認 goto out; pud = pud_offset(pgd, address); if (pud_none(*pud) || unlikely(pud_bad(*pud))) goto out; pmd = pmd_offset(pud, address); if (pmd_none(*pmd) || unlikely(pmd_bad(*pmd))) goto out; if (pmd_huge(*pmd)) return follow_huge_pmd(mm, address, pmd, write); ptep = pte_offset_map(pmd, address); // 仮想アドレスに対応するページテーブルエントリのアドレスを返す if (!ptep) goto out; pte = *ptep; pte_unmap(ptep); // pte_offset_map後に呼ぶ- linux-2.6.12.1/include/asm-*/pgtable.h
-
オフセットの取得やエントリの持つ情報は,アーキテクチャ依存であり,アーキテクチャごとに関数やマクロなどが定義されている。
例えばi386ならばasm-i386内の,sparcならばasm-sparc内のpgtable.hでマクロとして定義されていたり,関数の宣言があったりする。
以下にいくつかのマクロの実装例を示す(asm-arm/pgtable.h)。関数/マクロ 説明 pte_dirty ページが書き換えられたか判定。 pte_young ページがアクセスされたか判定。 pte_mkyoung ページがアクセスされたという情報をクリア。 pte_mkexec ページが実行不能にする。
これらの名前のマクロは,アーキテクチャによっては同名の関数の場合もある。#define L_PTE_PRESENT (1 << 0) #define L_PTE_FILE (1 << 1) /* only when !PRESENT */ #define L_PTE_YOUNG (1 << 1) #define L_PTE_BUFFERABLE (1 << 2) /* matches PTE */ #define L_PTE_CACHEABLE (1 << 3) /* matches PTE */ #define L_PTE_USER (1 << 4) #define L_PTE_WRITE (1 << 5) #define L_PTE_EXEC (1 << 6) #define L_PTE_DIRTY (1 << 7) #define pte_read(pte) (pte_val(pte) &L_PTE_USER) #define pte_write(pte) (pte_val(pte) &L_PTE_WRITE) #define pte_exec(pte) (pte_val(pte) &L_PTE_EXEC) #define pte_none(pte) (!pte_val(pte)) #define pte_dirty(pte) (pte_val(pte) &L_PTE_DIRTY) - linux-2.6.12.1/include/asm-*/pgalloc.h
-
以下にマクロの実装例を示す(asm-arm/pgalloc.h)。関数/マクロ 説明 pgd_alloc ページグローバルディレクトリの作成。 pgd_free ページグローバルディレクトリの解放。 pgd_none ページグローバルディレクトリのエントリが空かどうかの判定。 pte_none ページテーブルのエントリが空かどうかの判定。 extern pgd_t *get_pgd_slow(struct mm_struct *mm); #define pgd_alloc(mm) get_pgd_slow(mm) #define pgd_free(pgd) free_pgd_slow(pgd) #define pmd_alloc_one(mm,addr) ({ BUG(); ((pmd_t *)2); }) #define pmd_free(pmd) do { } while (0)
これらの名前のマクロは,アーキテクチャによっては同名の関数の場合もある。
ページフォルト
アクセスしたページがメモリ上にロードされていなかった(有効ビットがオフだった)場合,MMUはページフォルト割り込み(例外)を発生する。ページフォールトが発生すると,ハードウェアかソフトウェアによってメモリにロードされる。Linuxの場合はOSがその処理を行う。ページフォルトが発生した場合のOSの処理は次のような流れである。
- 仮想アドレスを使用してページテーブルのエントリを参照し,参照された物理ページが格納されたディスクの位置を見つけ出す。
- ページ置き換えアルゴリズムにしたがって,置き換え対象の物理ページを選択し,選択したページのダーティビットがオンである場合,先にその物理ページをディスクに書き戻す。
- 参照されたページをディスクから選択した物理ページに入れる。
Linuxでは,ページフォルト例外の処理はdo_page_fault関数で実装され,そのコードはアーキテクチャに依存する。例えばarmならば,arch/arm/mm/fault.cで,x86_64ならばarch/x86_64/mm/fault.cで定義される。
TLB
MMUの処理を高速化するために,プロセッサは,頻繁にアクセスするページテーブルのエントリを格納するTLB(Transfer Lookaside Buffer)というキャッシュメモリを持つ。TLBの各エントリは基本的にページテーブルと同様の内容であるが,有効ビットだけは意味が異なる。TLBに格納されたページは必ずページテーブルにも存在し,かつメモリ上に存在する。もしそのページがディスクに追い出される場合,TLBのそのエントリはクリアされる。TLBの有効ビットは命令やデータを格納するキャッシュメモリ同様,そのエントリが使用されているかどうかを表す。
TLBはプロセスごとに生成されるページテーブルとは異なり,全てのプロセスで共通して使用される。そして,各プロセスはそれぞれ同じ仮想アドレスを使用する。それゆえ,プロセス切り替えの際にTLBのエントリをクリアしなければ,あるプロセスのメモリ空間に対し,他のプロセスがアクセスするような事態に陥る。TLBのエントリの追加はハードウェアによって自動的に行われるが,TLB情報のクリアはソフトウェア(OS)によって行われる。
- include/asm-*/tlbflush.h
以下にマクロの実装例を示す(asm-i386/tlbflush.h)。関数/マクロ 説明 flush_tlb_all TLBのすべてのエントリをフラッシュ。 flush_tlb_mm 指定した仮想アドレス空間に関連するエントリをフラッシュ。 flush_tlb_range 指定した仮想アドレス空間の中の指定したアドレス範囲のエントリをフラッシュ。 flush_tlb_page 指定した仮想アドレス空間の中の指定した1ページのエントリをフラッシュ。
これらのマクロは,アーキテクチャによっては同名の関数かもしれないし,その逆かもしれない。#define __flush_tlb() \ do { \ unsigned int tmpreg; \ \ __asm__ __volatile__( \ "movl %%cr3, %0; \n" \ "movl %0, %%cr3; # flush TLB \n" \ : "=r" (tmpreg) \ :: "memory"); \ } while (0) # define __flush_tlb_all() \ do { \ if (cpu_has_pge) \ __flush_tlb_global(); \ else \ __flush_tlb(); \ } while (0) #define flush_tlb() __flush_tlb() #define flush_tlb_all() __flush_tlb_all()
アーキテクチャによってはキャッシュメモリで使用されるアドレスは,仮想アドレスであり,そのようなアーキテクチャの場合,OSによるクリアが必要である。
- include/asm-*/cacheflush.h
以下にマクロの実装例を示す(asm-arm/cacheflush.h)。関数/マクロ 説明 flush_cache_mm 指定した仮想アドレス空間に関連するキャッシュをクリア。 flush_cache_range 指定した仮想アドレス空間の中の指定したアドレス範囲のキャッシュをクリア。 flush_cache_page 指定した仮想アドレス空間に関連するキャッシュをクリア。 。
これらのマクロは,アーキテクチャによっては同名の関数かもしれないし,その逆かもしれない。ちなみにi386系は物理アドレスが使用されるため,何もしない実装となっている(共通コードの関係上マクロは呼び出されるが)。以下に"asm-i386/cacheflush.h"の一部を示す。static inline void flush_cache_mm(struct mm_struct *mm) { if (cpu_isset(smp_processor_id(), mm->cpu_vm_mask)) __cpuc_flush_user_all(); } static inline void flush_cache_range(struct vm_area_struct *vma, unsigned long start, unsigned long end) { if (cpu_isset(smp_processor_id(), vma->vm_mm->cpu_vm_mask)) __cpuc_flush_user_range(start &PAGE_MASK, PAGE_ALIGN(end), vma->vm_flags); } static inline void flush_cache_page(struct vm_area_struct *vma, unsigned long user_addr, unsigned long pfn) { if (cpu_isset(smp_processor_id(), vma->vm_mm->cpu_vm_mask)) { unsigned long addr = user_addr &PAGE_MASK; __cpuc_flush_user_range(addr, addr + PAGE_SIZE, vma->vm_flags); } }#define flush_cache_all() do { } while (0) #define flush_cache_mm(mm) do { } while (0) #define flush_cache_range(vma, start, end) do { } while (0) #define flush_cache_page(vma, vmaddr, pfn) do { } while (0)
ユーザ空間(セグメント)
典型的なUNIX系OSのユーザ空間は下図のようなレイアウトである。
| テキスト |
| データ |
| ヒープ |
| 共有ライブラリテキスト |
| 共有ライブラリデータ |
| スタック |
- テキスト領域
- コードが格納される領域。
- データ領域
- 静的なデータ(Cのグローバル変数やstatic変数)が格納される領域。静的なデータは初期値が0のものととそれ以外に分類され,それぞれメモリの初期化方法が異なる(0であればサイズだけ分かれば良いため)。前者の領域はBSSセクションやBSSセグメントと呼ばれる。アーキテクチャによっては書き換え不能なRODATA領域もある。
- ヒープ領域
- 動的メモリ確保で使用される(Cのmallocで使用される)領域。アドレスの大きな方に向かって領域を広げる。
- スタック領域
-
プログラム(主に関数)によって自動で確保される領域。Cではローカル変数や演算の返り値などの一時データを格納するのに使用される。ある関数が使用しているスタック領域の範囲をフレームという。静的変数が常に同じアドレスであるのに対し,ローカル変数はフレームの先頭位置か終了位置から相対的にアドレスを指す。それゆえ,ローカル変数は毎回アドレスが違う。
ちなみにこのような仕組みのおかげで関数の再帰呼び出しが可能である。スタック フレームA フレームB
プログラムが使用する仮想アドレスはリンカによって解決され,プログラムを実行する際にプログラムローダ(OSの機能)によってメモリ上に運ばれる。
ページテーブルは,forkシステムコールによって親のページテーブルを複製したものが使用される。
コピーオンライト
書き込み時にメモリコピーを行うことでメモリ管理の利用効率を高める方法。初期のUNIXでは,forkが呼ばれた度にページテーブルや使用するページの複製を生成し,ページテーブルが指すページを新たに生成したものに変更していた。
- 親プロセス
仮想メモリ 物理メモリ 読み込み可能 書き込み可能 0x00000 0x0100A true false 0x00001 0x03A08 true false ... 0xFFFFE 0x8FC07 true true 0xFFFFF 0x9F05C true true - 子プロセス
仮想メモリ 物理メモリ 読み込み可能 書き込み可能 0x00000 0x0208A true false 0x00001 0x08531 true false ... 0xFFFFE 0x2031B true true 0xFFFFF 0x7F3B1 true true
- 親プロセス
仮想メモリ 物理メモリ 読み込み可能 書き込み可能 0x00000 0x0100A true false 0x00001 0x03A08 true false ... 0xFFFFE 0x8FC07 true false 0xFFFFF 0x9F05C true false - 子プロセス
仮想メモリ 物理メモリ 読み込み可能 書き込み可能 0x00000 0x0100A true false 0x00001 0x03A08 true false ... 0xFFFFE 0x8FC07 true false 0xFFFFF 0x9F05C true false - kernel/fork.c
プロセス空間を共有する場合は,mm_struct構造体を共有するため,親プロセスのmm_struct構造体のmm_usersメンバをインクリメントするだけで良い。static int copy_mm(unsigned long clone_flags, struct task_struct * tsk) { struct mm_struct * mm, *oldmm; int retval; tsk->min_flt = tsk->maj_flt = 0; tsk->nvcsw = tsk->nivcsw = 0; tsk->mm = NULL; tsk->active_mm = NULL; /* * Are we cloning a kernel thread? * * We need to steal a active VM for that.. */ oldmm = current->mm; if (!oldmm) return 0;if (clone_flags & CLONE_VM) { atomic_inc(&oldmm->mm_users); mm = oldmm; /* * There are cases where the PTL is held to ensure no * new threads start up in user mode using an mm, which * allows optimizing out ipis; the tlb_gather_mmu code * is an example. */ spin_unlock_wait(&oldmm->page_table_lock); goto good_mm; }- mm_struct構造体の割り当て。mm_cachepスラブから割り当てを受ける。
- mm_structオブジェクトのメンバの初期化。start_codeなど,プログラムに関するメンバは親プロセスのものがコピーされる。
- ページグローバルディレクトリの割り当て。
- コンテキストの割り当て。
- プロセス空間のコピー。dup_mmap関数(kernel/fork.c)によって vm_area_structオブジェクトの割り当てと設定。コピーオンライトを行うため,vm_area_structにVM_MAYWRITEが設定されている場合,親も子も書き込み禁止にする。
retval = -ENOMEM; mm = allocate_mm(); if (!mm) goto fail_nomem; /* Copy the current MM stuff.. */ memcpy(mm, oldmm, sizeof(*mm)); if (!mm_init(mm)) goto fail_nomem; if (init_new_context(tsk,mm)) goto fail_nocontext; retval = dup_mmap(mm, oldmm); if (retval) goto free_pt; mm->hiwater_rss = get_mm_counter(mm,rss); mm->hiwater_vm = mm->total_vm; good_mm: tsk->mm = mm; tsk->active_mm = mm; return 0; free_pt: mmput(mm); fail_nomem: return retval; fail_nocontext: /* * If init_new_context() failed, we cannot use mmput() to free the mm * because it calls destroy_context() */ mm_free_pgd(mm); free_mm(mm); return retval; }- ページテーブルに書かれた実ページやスワップ領域の解放。
- ページテーブルの解放。
- ファイル構造体の参照カウントをデクリメントしたりvm_area_struct構造体の解放したりする。
- mm/mmap.c
/* Release all mmaps. */ void exit_mmap(struct mm_struct *mm) { struct mmu_gather *tlb; struct vm_area_struct *vma = mm->mmap; unsigned long nr_accounted = 0; unsigned long end; lru_add_drain(); spin_lock(&mm->page_table_lock); flush_cache_mm(mm); tlb = tlb_gather_mmu(mm, 1); /* Use -1 here to ensure all VMAs in the mm are unmapped */ end = unmap_vmas(&tlb, mm, vma, 0, -1, &nr_accounted, NULL); // 実ページやスワップ領域の解放 vm_unacct_memory(nr_accounted); free_pgtables(&tlb, vma, FIRST_USER_ADDRESS, 0); // ページテーブルの解放 tlb_finish_mmu(tlb, 0, end); mm->mmap = mm->mmap_cache = NULL; mm->mm_rb = RB_ROOT; set_mm_counter(mm, rss, 0); mm->total_vm = 0; mm->locked_vm = 0; spin_unlock(&mm->page_table_lock); /* * Walk the list again, actually closing and freeing it * without holding any MM locks. */ while (vma) { struct vm_area_struct *next = vma->vm_next; remove_vm_struct(vma); vma = next; } BUG_ON(mm->nr_ptes > (FIRST_USER_ADDRESS+PMD_SIZE-1)>>PMD_SHIFT); }- ストレートマップ領域
- 物理メモリにアクセスするための領域。カーネルは全ての実メモリにアクセスできる必要がある。そしてそのためにストレートマップ領域では「仮想アドレス=実アドレス+PAGE_OFFSET」の関係でマッピングされている(PAGE_OFFSETはマクロで,ストレートマップ領域の先頭アドレスを表す)。i386系では最大896MBのサイズで,実メモリがそれ以上の場合,HIGHMEMアクセス領域にマッピングされる。
- HIGHMEMアクセス領域
- ストレートマップ領域にマッピングできなかった実メモリにアクセスするための領域。HIGHMEMアクセス領域は専用のインタフェースによってアクセスする。そのインタフェースは,指定したページがストレートマップ領域ならば仮想アドレスを,HIGHMEMであればページテーブルにマッピングして,その仮想アドレスを返す。
- 固定マップ領域
-
固定の仮想アドレスで任意の実アドレスにアクセスするための領域。固定マップ領域の用途はinclude/asm-*/fixmap.hの「enum fixed_addresses」を参照されたし。
- include/asm-i386/fixmap.h
enum fixed_addresses { FIX_HOLE, FIX_VSYSCALL, #ifdef CONFIG_X86_LOCAL_APIC FIX_APIC_BASE, /* local (CPU) APIC) -- required for SMP or not */ #endif #ifdef CONFIG_X86_IO_APIC FIX_IO_APIC_BASE_0, FIX_IO_APIC_BASE_END = FIX_IO_APIC_BASE_0 + MAX_IO_APICS-1, #endif #ifdef CONFIG_X86_VISWS_APIC FIX_CO_CPU, /* Cobalt timer */ FIX_CO_APIC, /* Cobalt APIC Redirection Table */ FIX_LI_PCIA, /* Lithium PCI Bridge A */ FIX_LI_PCIB, /* Lithium PCI Bridge B */ #endif #ifdef CONFIG_X86_F00F_BUG FIX_F00F_IDT, /* Virtual mapping for IDT */ #endif #ifdef CONFIG_X86_CYCLONE_TIMER FIX_CYCLONE_TIMER, /*cyclone timer register*/ #endif #ifdef CONFIG_HIGHMEM FIX_KMAP_BEGIN, /* reserved pte's for temporary kernel mappings */ FIX_KMAP_END = FIX_KMAP_BEGIN+(KM_TYPE_NR*NR_CPUS)-1, #endif #ifdef CONFIG_ACPI_BOOT FIX_ACPI_BEGIN, FIX_ACPI_END = FIX_ACPI_BEGIN + FIX_ACPI_PAGES - 1, #endif #ifdef CONFIG_PCI_MMCONFIG FIX_PCIE_MCFG, #endif __end_of_permanent_fixed_addresses, /* temporary boot-time mappings, used before ioremap() is functional */ #define NR_FIX_BTMAPS 16 FIX_BTMAP_END = __end_of_permanent_fixed_addresses, FIX_BTMAP_BEGIN = FIX_BTMAP_END + NR_FIX_BTMAPS - 1, FIX_WP_TEST, __end_of_fixed_addresses };
- カーネル仮想領域
-
カーネルが自身の作業をするのに使用する領域。以下に示す関数などを使用して,必要に応じて仮想メモリを割り当て,そこで作業を行う。いくつかのアーキテクチャでは,カーネルモジュールをロードするために使用される。
- include/linux/vmalloc.h
extern void *vmalloc(unsigned long size); extern void vfree(void *addr); extern void *vmap(struct page **pages, unsigned int count, unsigned long flags, pgprot_t prot); extern void vunmap(void *addr);
マクロ 説明 VMALLOC_START 開始位置 VMALLOC_END 終了位置 - ノード
-
Linuxでは,同じメモリアクセス特性を持つ物理メモリ領域毎に管理することで,さまざまなアーキテクチャに対応させ,かつそれらを効率的に利用する仕組みがある。
- NUMA(Non-Uniform Memory Access)システム
- 共有メモリ型マルチプロセッサのうち,全てのプロセッサとメモリの距離が一定でないもの。NUMAアーキテクチャでは,プロセッサとメモリの対のことをノードという。NUMAシステムは複数のノードから構成され,全てのノードはインターコネクトで接続されている。NUMAシステムでは,プロセッサとメモリの距離に応じてアクセス速度が異なる(すなわちメモリアクセス特性が異なる)。 例えば,あるノードのプロセッサが同じノードのメモリ(ローカルメモリ)にアクセスするのと,別のノードのメモリ(リモートメモリ)にアクセスするのではローカルメモリの方が速い。ページ管理では,アクセス頻度が高い領域をローカルメモリに,アクセス頻度が低い領域をリモートメモリに割り当てた方が高い性能が期待できる。
- 非連続メモリ領域
- 複数の物理メモリ領域を持つアーキテクチャの場合,各物理メモリ領域毎に管理することで対応する(物理的なメモリ数ではなくアドレス空間が複数ある場合の話)。
- ゾーン
-
Linuxでは,実メモリはアドレスに応じてゾーンに分類される。ゾーンの種類はアーキテクチャによって異なる。例えばia32やx86_64では以下のようになる。
ゾーン 領域 ia32 ZONE_DMA ストレートマップ領域 16MB未満 ZONE_NORMAL 16MB以上896MB未満 ZONE_HIGHMEM その他の領域 896MB以上 - linux-2.6.12.1/include/linux/mmzone.h
/* * On machines where it is needed (eg PCs) we divide physical memory * into multiple physical zones. On a PC we have 3 zones: * * ZONE_DMA < 16 MB ISA DMA capable memory * ZONE_NORMAL 16-896 MB direct mapped by the kernel * ZONE_HIGHMEM > 896 MB only page cache and user processes */#define ZONE_DMA 0 #define ZONE_NORMAL 1 #define ZONE_HIGHMEM 2
- pglist_data構造体(include/linux/mmzone.h)
-
pglist_dataはノード毎にメモリを管理するための制御表である。メンバには次のようなものがある。
メンバ 説明 node_zones ノードに属するゾーン node_zonelists 空きページ獲得時の検索順 nr_zones ノードに属するゾーン数 node_mem_map ノードに属するページ node_id ノード番号 pgdat_next ノードリスト用の次へのポインタ
前述したZONE_DMAやZONE_NORMALなどのマクロは,node_zonesの添字として使用される。typedef struct pglist_data { struct zone node_zones[MAX_NR_ZONES]; struct zonelist node_zonelists[GFP_ZONETYPES]; int nr_zones; struct page *node_mem_map; struct bootmem_data *bdata; unsigned long node_start_pfn; unsigned long node_present_pages; /* total number of physical pages */ unsigned long node_spanned_pages; /* total size of physical page range, including holes */ int node_id; struct pglist_data *pgdat_next; wait_queue_head_t kswapd_wait; struct task_struct *kswapd; int kswapd_max_order; } pg_data_t; - zone構造体(include/linux/mmzone.h)
-
ゾーンはzone構造体で管理される。
メンバ 説明 free_pages フリーなページ数 pages_min 空きページの確保量(min<low<high) pages_low pages_high zone_mem_map ゾーンに属するページ free_area バディシステム管理 name ゾーン名 struct zone { /* Fields commonly accessed by the page allocator */ unsigned long free_pages; unsigned long pages_min, pages_low, pages_high; /* * We don't know if the memory that we're going to allocate will be freeable * or/and it will be released eventually, so to avoid totally wasting several * GB of ram we must reserve some of the lower zone memory (otherwise we risk * to run OOM on the lower zones despite there's tons of freeable ram * on the higher zones). This array is recalculated at runtime if the * sysctl_lowmem_reserve_ratio sysctl changes. */ unsigned long lowmem_reserve[MAX_NR_ZONES]; struct per_cpu_pageset pageset[NR_CPUS]; /* * free areas of different sizes */ spinlock_t lock; struct free_area free_area[MAX_ORDER]; ZONE_PADDING(_pad1_) /* Fields commonly accessed by the page reclaim scanner */ spinlock_t lru_lock; struct list_head active_list; struct list_head inactive_list; unsigned long nr_scan_active; unsigned long nr_scan_inactive; unsigned long nr_active; unsigned long nr_inactive; unsigned long pages_scanned; /* since last reclaim */ int all_unreclaimable; /* All pages pinned */ /* * prev_priority holds the scanning priority for this zone. It is * defined as the scanning priority at which we achieved our reclaim * target at the previous try_to_free_pages() or balance_pgdat() * invokation. * * We use prev_priority as a measure of how much stress page reclaim is * under - it drives the swappiness decision: whether to unmap mapped * pages. * * temp_priority is used to remember the scanning priority at which * this zone was successfully refilled to free_pages == pages_high. * * Access to both these fields is quite racy even on uniprocessor. But * it is expected to average out OK. */ int temp_priority; int prev_priority; ZONE_PADDING(_pad2_) /* Rarely used or read-mostly fields */ /* * wait_table -- the array holding the hash table * wait_table_size -- the size of the hash table array * wait_table_bits -- wait_table_size == (1 << wait_table_bits) * * The purpose of all these is to keep track of the people * waiting for a page to become available and make them * runnable again when possible. The trouble is that this * consumes a lot of space, especially when so few things * wait on pages at a given time. So instead of using * per-page waitqueues, we use a waitqueue hash table. * * The bucket discipline is to sleep on the same queue when * colliding and wake all in that wait queue when removing. * When something wakes, it must check to be sure its page is * truly available, a la thundering herd. The cost of a * collision is great, but given the expected load of the * table, they should be so rare as to be outweighed by the * benefits from the saved space. * * __wait_on_page_locked() and unlock_page() in mm/filemap.c, are the * primary users of these fields, and in mm/page_alloc.c * free_area_init_core() performs the initialization of them. */ wait_queue_head_t * wait_table; unsigned long wait_table_size; unsigned long wait_table_bits; /* * Discontig memory support fields. */ struct pglist_data *zone_pgdat; struct page *zone_mem_map; /* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */ unsigned long zone_start_pfn; unsigned long spanned_pages; /* total size, including holes */ unsigned long present_pages; /* amount of memory (excluding holes) */ /* * rarely used fields: */ char *name; } ____cacheline_maxaligned_in_smp; - page構造体(include/linux/mm.h)
-
実メモリはpage構造体で管理される。
ページ管理に使用される構造体のメンバの一部を紹介する。
以下に実際のstruct pageの定義部分を示す。メンバ 説明 flags ページの状態(フラグはinclude/linux/page-flags.hで定義されている) _count ページの参照カウント _mapcount アドレス空間にマッピングされている数 mapping ファイルキャッシュとして使用されているとき,そのアドレススペース構造体 index ページ単位のファイルオフセット,またはスワップ領域のインデックス(mappingがスワップキャッシュの場合) lru LRUリスト用 virtual kmapされているとき,その仮想アドレス struct page { page_flags_t flags; /* Atomic flags, some possibly * updated asynchronously */ atomic_t _count; /* Usage count, see below. */ atomic_t _mapcount; /* Count of ptes mapped in mms, * to show when page is mapped * & limit reverse map searches. */ unsigned long private; /* Mapping-private opaque data: * usually used for buffer_heads * if PagePrivate set; used for * swp_entry_t if PageSwapCache * When page is free, this indicates * order in the buddy system. */ struct address_space *mapping; /* If low bit clear, points to * inode address_space, or NULL. * If page mapped as anonymous * memory, low bit is set, and * it points to anon_vma object: * see PAGE_MAPPING_ANON below. */ pgoff_t index; /* Our offset within mapping. */ struct list_head lru; /* Pageout list, eg. active_list * protected by zone->lru_lock ! */ /* * On machines where all RAM is mapped into kernel address space, * we can simply calculate the virtual address. On machines with * highmem some memory is mapped into kernel virtual memory * dynamically, so we need a place to store that address. * Note that this field could be 16 bits on x86 ... ;) * * Architectures with slow multiplication can define * WANT_PAGE_VIRTUAL in asm/page.h */ #if defined(WANT_PAGE_VIRTUAL) void *virtual; /* Kernel virtual address (NULL if not kmapped, ie. highmem) */ #endif /* WANT_PAGE_VIRTUAL */ };- ページフラグ(include/linux/page-flags.h)
-
ページのフラグ(page構造体のflagsメンバ)で使用される値は次の通りである。
以下に前述のマクロらの定義部分を示す。名前 説明 PG_locked ロックされている PG_error IO中のエラー発生 PG_referenced 参照された PG_uptodate 読み込みIO完了 PG_dirty 書き込みがあった PG_writeback ライトバック中 PG_reclaim スワップ処理中 PG_lru LRUリストにつながっている PG_checked チェック済み(filesystemで使用)。 PG_swapcache スワップキャッシュとして使用 #define PG_locked 0 /* Page is locked. Don't touch. */ #define PG_error 1 #define PG_referenced 2 #define PG_uptodate 3 #define PG_dirty 4 #define PG_lru 5 #define PG_active 6 #define PG_slab 7 /* slab debug (Suparna wants this) */ #define PG_highmem 8 #define PG_checked 9 /* kill me in 2.5.<early>. */ #define PG_arch_1 10 #define PG_reserved 11 #define PG_private 12 /* Has something at ->private */ #define PG_writeback 13 /* Page is under writeback */ #define PG_nosave 14 /* Used for system suspend/resume */ #define PG_compound 15 /* Part of a compound page */ #define PG_swapcache 16 /* Swap page: swp_entry_t in private */ #define PG_mappedtodisk 17 /* Has blocks allocated on-disk */ #define PG_reclaim 18 /* To be reclaimed asap */ #define PG_nosave_free 19 /* Free, should not be written */ #define PG_uncached 20 /* Page has been mapped as uncached */
- 20=1
- 21=2
- 22=4
- 23=8
- ...
- 211=2048
- include/linux/mmzone.h
#define MAX_ORDER 11 struct free_area { struct list_head free_list; unsigned long nr_free; };- include/linux/list.h
struct list_head { struct list_head *next, *prev; };
fork
UNIX系OSでは,forkシステムコールを使用して親プロセスのコピーを作ることでプロセスを生成する。親プロセスの領域から子プロセスの領域へのコピーは,copy_mm関数で行われている。
mmap
UNIX系OSは,ファイルの一部,または全体をプロセス空間にマップしてメモリの一部のように使用するファイルマップ機能がある。ユーザはファイルマップをmmapシステムコールを使用して行うことができる。
通常,ファイルのアクセスはreadシステムコールやwriteシステムコールを使用して行う。この時,カーネルはファイルのデータをカーネル内のバッファ(ファイルキャッシュ)にコピーした上で,プロセス空間にコピーする。mmapはこのバッファをページ単位として,プロセス空間にマップすることで,ファイルマップを行う。mmapはdo_mmap関数として実装される。do_mmap関数はmmapシステムコールのためだけでなく,メモリ領域を確保する場合にも使用される。do_mmap関数はmm/mmap.cのdo_mmap_pgoff関数を呼び出し,これが実際の処理を行う。
exec
UNIX系OSでは,execシステムコールを使用することで,任意のプログラムを実行できる。execでは,新たなmm_struct構造体が割り当てられ,古いmm_struct構造体が解放される。新しいmm_struct構造体にはvm_area_struct構造体やプログラムに関するメンバも未設定で,これらを新しく設定する。execはプロセスのスタック領域とヒープ領域を確保し,テキスト領域やデータ領域は,カーネルのdo_mmap関数によってファイルマップされる。
brk
brkはヒープ領域の拡張を行うシステムコールであり,mm/mmap.cのdo_brk関数として実装される。do_brkは前述のdo_mmap_pgoff関数の簡略版である。
exit
exitはプロセスの終了時に呼び出されるシステムコールである。プロセス空間の領域はmm/mmap.cのexit_mmap関数で行われる。
カーネル空間
カーネルもまた基本的には仮想アドレス空間上で動作する。i386系のカーネル空間レイアウトは次の通りである。
| ユーザ空間 | |
| カーネル空間 | ストレートマップ |
| カーネル仮想領域 | |
| HIGHMEMアクセス領域 | |
| 固定マップ領域 | |
実ページ管理
Linuxは実ページを階層的に管理する。
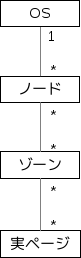
カーネルは「struct pglist_data」のポインタであるpgdat_listという変数を持ち,これを使用して各ノードを管理する。
空きページの管理(バディシステム)
バディシステムは空きページを2のべき乗の単位で管理する。
struct free_area free_area[MAX_ORDER];実ページの獲得,解放のインタフェースはpage構造体やアドレスを返す。これらの関数はmm/page_alloc.cやinclude/linux/gfp.hらで定義されている。
| 関数 | 備考 |
|---|---|
| unsigned long __get_free_pages(unsigned int __nocast gfp_mask, unsigned int order) | |
| struct page *alloc_pages(unsigned int __nocast gfp_mask, unsigned int order) | gfp_maskのフラグについてはinclude/linux/gfp.hの__GFP_やGFP_の接頭辞のマクロを参照。 |
| fastcall void __free_pages(struct page *page, unsigned int order) | |
| fastcall void free_pages(unsigned long addr, unsigned int order) |